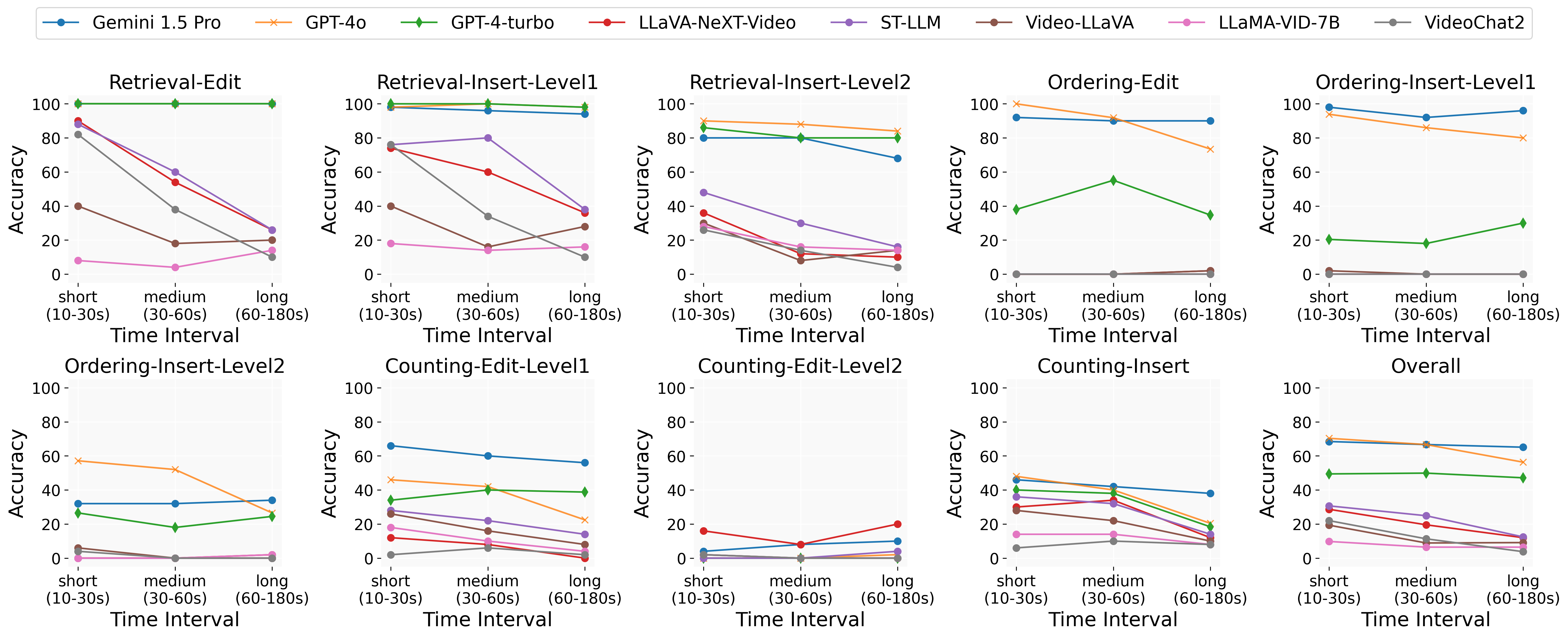
VNBench contains 3 task: Retrieval, Ordering and Counting. Each task is divided into 3 sub-tasks according to the needle type and task difficulty.
| Video MLLMs | Retrieval | Ordering | Counting | Overall | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E | I-1 | I-2 | Avg. | E | I-1 | I-2 | Avg. | E-1 | E-2 | I | Avg. | ||
| Gemini 1.5 Pro * | 100.0 | 96.0 | 76.0 | 90.7 | 90.7 | 95.3 | 32.7 | 72.9 | 60.7 | 7.3 | 42.0 | 36.7 | 66.7 |
| Aria | 100.0 | 100.0 | 49.3 | 83.1 | 88.7 | 96.0 | 58.0 | 80.9 | 54.7 | 11.3 | 38.7 | 34.9 | 66.3 |
| GPT-4o * | 100.0 | 98.0 | 87.3 | 95.3 | 88.4 | 86.6 | 45.2 | 73.4 | 36.8 | 0.0 | 36.1 | 24.5 | 64.4 |
| Video-XL-7B | 98.0 | 93.3 | 48.7 | 80.0 | 89.3 | 77.3 | 75.3 | 80.6 | 38.7 | 7.3 | 26.0 | 24.0 | 61.6 |
| LongLLaVA-A13 | 100.0 | 100.0 | 73.3 | 91.1 | 37.5 | 35.3 | 34.8 | 35.9 | 36.0 | 23.7 | 28.0 | 29.2 | 52.1 |
| LLaVA-OneVision-7B | 88.7 | 87.3 | 55.3 | 77.1 | 70.0 | 50.0 | 37.3 | 52.4 | 41.3 | 8.7 | 27.3 | 25.8 | 51.8 |
| GPT-4-Turbo * | 100.0 | 99.3 | 82.0 | 93.7 | 42.6 | 22.8 | 23.0 | 29.5 | 37.6 | 0.0 | 32.4 | 23.3 | 48.9 |
| Qwen2-VL-7B | 98.0 | 76.0 | 33.3 | 69.1 | 16.0 | 12.7 | 8.7 | 12.4 | 26.0 | 9.3 | 24.7 | 20.0 | 33.9 |
| ST-LLM | 58.0 | 64.7 | 31.3 | 51.3 | 0.0 | 0.0 | 0.0 | 0.0 | 21.3 | 1.3 | 27.3 | 16.7 | 22.7 |
| LLaVA-NeXT-Video | 56.7 | 56.7 | 19.3 | 44.2 | 0.7 | 0.0 | 0.7 | 0.4 | 6.7 | 14.6 | 25.3 | 15.5 | 20.1 |
| VideoChat2 | 43.4 | 40.0 | 14.6 | 32.7 | 0.0 | 0.0 | 1.3 | 0.4 | 3.3 | 0.7 | 8.0 | 4.0 | 12.4 |
| Video-LLaVA | 26.0 | 28.0 | 17.3 | 23.8 | 0.7 | 0.7 | 2.0 | 1.1 | 16.7 | 0.7 | 20.0 | 12.4 | 12.4 |
| LLaMA-VID | 28.0 | 28.0 | 19.3 | 25.1 | 0.7 | 0.0 | 0.0 | 0.2 | 4.0 | 2.7 | 14.7 | 7.1 | 10.8 |
| Video-LLaMA2 | 1.2 | 26.0 | 6.0 | 11.1 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 4.7 | 0.7 | 2.4 | 4.5 |
| VideoChatGPT | 4.7 | 4.7 | 0.7 | 3.3 | 2.7 | 11.3 | 0.0 | 4.7 | 2.0 | 4.0 | 6.7 | 4.2 | 4.1 |
* indicates proprietary models